분석한 데이타를 항상 줄줄이 읊으면서 페이퍼에 보고하지 않는다. 어떨땐 표를 사용해서 기술치를 전부 한 표에 집어 넣어 간결하고 보기 좋게 제시하기도 하고, 그래프를 통해서 한눈에 데이타 특징을 볼 수 있게 나타내기도 한다. 많은 사람들이 SPSS를 사용하고 있는데, SPSS의 단점 중 하나는 그래프가 너무 못났다. 내가 SPSS를 사용할 때에는 SPSS에서 나타난 그래프를 사용할 생각도 안했고, 따로 엑셀로 작업했어야 했다. R을 사용하면 엑셀로 이중 작업을 할 필요 없이 예쁘고 깔끔한 그래프를 그릴 수 있다.
여기서 예쁘고는 알록달록한 그래프가 아니라, 정말 깔끔하게 한눈에 잘 보이는 그런 그래프를 의미한다. 예쁜 그래프는...
- 심플해야함
- 최대한 색깔을 적게 사용해야함
- 의미를 분명히 전달하여야 함
- 최소한의 글을 포함해야함
R로 바로 넘어가기 전에 그래프에는 어떤 부분이 포함되어 있나 살펴보자.
데이타 (data)
- 어떤 변인을 그래프로 표현할 것인지?
- 한 변인만을 시각화 할 것인지, 두 개의 변이을 포함할 것인지?
- 변인은 어떻게 측정되었나?
- 변인의 유형은 무엇인지? 연속 변인인지 불연속 변인인지?
미적 특질 (aesthetic)
- 도표에서 시각적 영역
- 점: 크기, 모양, 색
- 막대: 크기, 모양, 색
척도 (scale)
- 측정 척도는 무엇인가
- 척도 전체를 보여줄 것인지, 측정 척도 내의 특정 변화를 보여줄 것인지?
- 축에는 몇개의 값을 보여줄 것인지
기하학적 모양 (geometric shapes)
- 막대
- 점
- 선
- 박스
통계치 (statistics)
- 통계적 수치가 있다면, 어떻게 포함할 것인지(평균, 중앙값, 변산도 등)
- 최적선 등
측면 (facets)
- 하위집단을 포함할 것인가
- 서로 다른 도표에 표시할 것인지, 함께 표시할 것인지?
- 집단은 어떻게 구분할 것인지? 색, 크기, 모양..?
좌표계(systematic coordinates)
- 디폴트는 평면좌표(x와 y축을 사용해 특정 값을 위치하는 도표)를 사용. coor_flip()를 사용하면 x축과 y축을 서로 바꿀 수 있음
- 파이 차트는 극좌표(polar coordinates)을 사용함
- 막대그래프와 파이차트는 좌표 차이 말고는 둘은 근본적으로 같음
이제 R을 통해서 실제로 그래프를 얻어보기로 하자. 먼저 아래 그림을 참고하여 데이타 클리닝을 해준 후 시작한다.

그래프를 구하기 위해서 ggplot2 package를 이용할 것이다. 시작 전에 꼭 install.packages("ggplot2"), library(ggplot)을 실행시킨 후 작업하자.
1. 불연속 변인 내 각각의 범주에 빈도를 표시하기
막대그래프
막대그래프를 그리기 위한 R코드는 다음과 같다.
ggplot(data=subset(data, !is.na(variable)), aes(x=as.factor(variable))) + geom_bar() +xlab("x axis name") + ylab("y axis name")+theme_classic()
자세히 코드가 무엇을 의미하는지 살펴보자
- data=subset(data, !is.na(variable)): 데이타를 설정해주고, 그 데이타 내 변인의 결측치를 무시하라는 명령어
- aes(x=as.factor(variable)): 변인을 불연속변인으로 설정 및 지정
- geom_bar(): 기하학적 모양 설정을 bar로 해줌. 안에 fill="color"를 추가하면, 해당되는 색으로 칠해진 막대그래프를 만날 수 있다.
- xlab("x axis name"): x축 이름 설정
- ylab("y axis name"): y축 이름 설정
- theme_classic(): ggplot에서는 theme_dark, theme_linedraw, theme_void 등등 사용할 수 있는 여러 theme이 있는데, 이 theme에 따라 그래프의 디자인이 약간씩 다르게 나온다. 우리는 클래식으로 사용하겠음.
위 코드를 우리 데이타에 적용해보자. 가족 소득에 따른 빈도를 구하기 위한 코드는 다음과 같다. 약간 복잡하지만 할만하다. 다음 코드를 입력하면 아래 사진처럼 그래프가 예쁘게 나온다. 가족 소득 외에도 성별, 사교육 유무 모두 불연속 변수이므로 연습해보는 것을 추천한다.
ggplot(data=subset(child_data, !is.na(famincome)), aes(x=as.factor(famincome))) + geom_bar(fill="grey") +xlab("Income") + ylab("Frequency")+theme_classic()

파이차트
파이차트는 pie 명령어를 쓰면 된다.
pie(table(data$factorvariable), labels= c("level1", "level2", "level3"), col=c("color1", "color2", "color3"), main="Chart name")
파이차트는 일반적으로 심리학에서 사용하지 말 것을 권장하는데, 실험 결과 사람들이 각도에 의한 크기 차이를 잘 인식하지 못하는 결과가 나왔기 때문이라고 했다. 그래서 나도 예시만 넣고 간단히 넘어가도록 하겠다. 아마 자세히 살펴보면 직관적으로 코드가 어떻게 짜여져있는지 알 수 있을 것이다.
pie(table(child_data$famincome), labels= c("Low", "Middle", "High"), col=c("red", "orange", "yellow"), main="Pie Chart ")

2. 연속변인: 변인의 각각의 관찰값에 대한 점수 나타내기
히스토그램(histograms)
이제 히스토그램을 그려보자. 히스토그램을 간단하게 설명하면 연속변인에 대해서 답변한(?) 값을 범위마다 빈도를 표현한 것이다. 히스토그램은 ggplot을 이용한 코드에서 geom_histogram()을 더해서 사용한다. 즉, 다음처럼 표시할 수 있다. 여기서 data=subset(data, !is.na =(contvariable))은 해당 연속변수에 대한 결측치를 무시하고 나머지를 서브데이타로 설정해서 돌리라는 것이다. 만약에 그냥 데이타만 입력해서 돌린다면 오류메시지가 나긴 하는데, 결측치때문이므로 그냥 data이름만으로 입력하고 돌려도 무관하다.
ggplot(data=subset(data, !is.na=(contvariable)), aes(x=contvariable))+geom_histogram()
ggplot(data=data, aes(x=contvariable))+geom_histogram()
우리의 예시를 보면, 아동의 삶의 만족도를 살펴보기로 한다. 삶의 만족도에 대한 히스토그램을 구하기 위한 코드값은 다음과 같다.
ggplot(data=subset(child_data, !is.na(stusatisf)), aes(x=stusatisf))+ geom_histogram()
혹은 ggplot(child_data, aes(x=stusatisf))+ geom_histogram()
실행하면 다음과 같은 결과가 나온다. 도표를 보면, 1~2사이가 다섯개로 나뉘어서 1.2까지의 값을 가진 빈도, 1.4까지의 값을 가진 빈도 등등 0.2를 기준점으로 해서 빈도수를 표현해줌을 볼 수 있다.
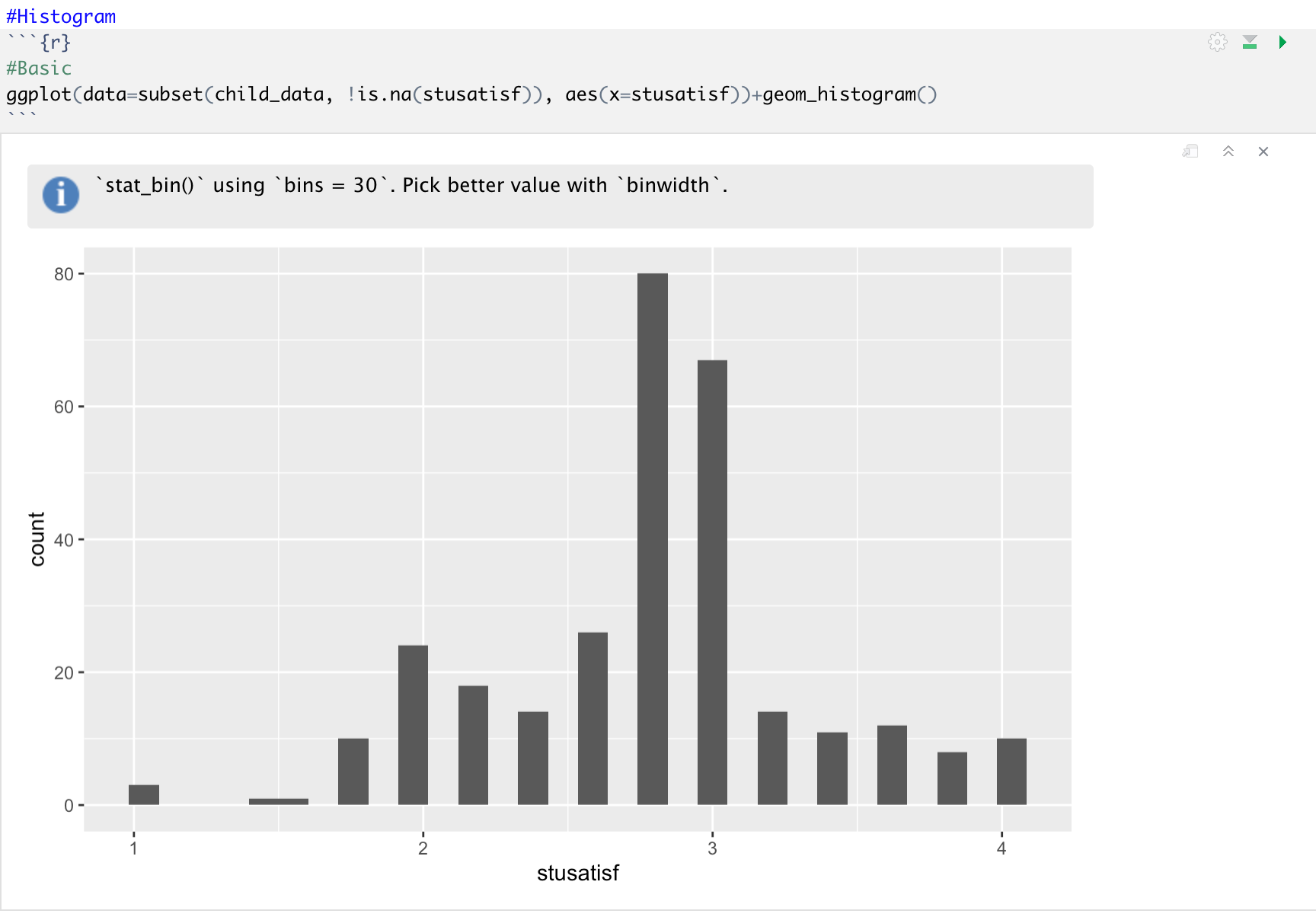
이 빈도수를 조정해서 빈도수를 구하고자 할 때는 어떻게 할까? 그럴 땐 geom_histogram()에 bin=숫자 로 표시해줄 수 있다, 다음을 찹고해보자.

이 히스토그램을 범주에 따라 표시 해본다고 생각해보자. 예를 들면, 학생 만족감의 빈도가 이만큼 있는데 이 중에 남자애들, 여자애들을 구분해서 표시하고자 한다면 다음과 같이 geom_histogram의 괄호 안에 aes(fill=as.factor(factor))을 더해볼 수 있다.

이제 옆에 as.factor(gender)이라고 나온 애를 예쁘게 수정해보자. scale+fill_discrete(name="")을 사용하면 옆에 각각 색으로 표시된 구분이 무엇인지 나타낼 수 있다.

각 성별에 따른 히스토그램을 따로따로 나타내고 싶으면 어떻게 할까? 이 때는 facet_wrap(~as.factor(gender))을 추가해주면 된다. 다음을 참고해서 직접 해보기로 하자!

박스그래프(boxplots)
박스그래프는 최소값, 최고값, 중앙값, 사분범위값을 모두 표기해주어서 분산도에 대한 많은 정보를 제공해줄 수 있다. 이제 박스그래프를 그려보자. 박스 그래프는 geom_boxplot()을 사용하면된다. 이를 사용하면 다음과 같이 코드를 입력할 수 있다.
ggplot(data=subset(child_data, !is.na(stusatisf)), aes(y=stusatisf))+geom_boxplot()
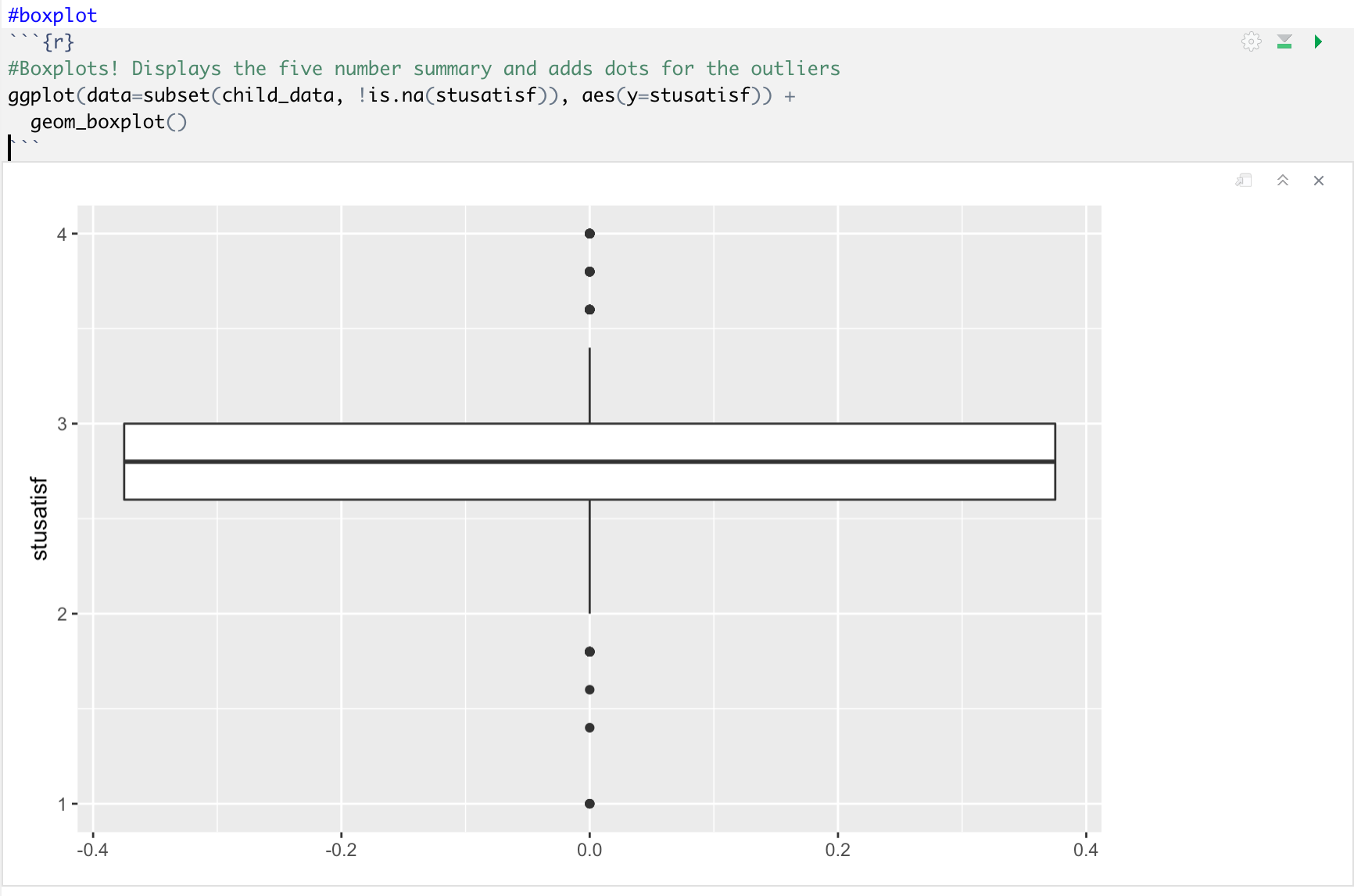
박스가 너무 길게 못나온 것 같으면, 박스를 다음 코드를 이용해서 줄이자. scale_x_discrete(limite=c("-0.5", "0.5"))를 + 기호를 이용해서 더해보면, x축의 왼쪽 최소값, 오른쪽 최댓값을 설정해주어 박스크기가 작고 예쁘게 나올 수 있다.

해당 변인에 대한 박스플롯을 요인에 따라 구하고자 한다면, 코드는 다음과 같이 사용할 수 있다. 왼쪽 남성, 오른쪽 여성의 박스플롯에 나온 것을 알 수 있다. 또 여기서 더해 stat_summary(fun.y=mean, geom="point")코드는 박스플롯에서 점으로 평균값을 표시하라는 명령어이므로 참고하도록 하자.

산포도(scatterplots)
산포도는 x변인에 대한 y변인에 대한 값을 한 평면에 표현한 그래프라고 할 수 있다. 상관에 대해서 배울 때 가장 많이 보는 그래프이다. 이 그래프는 R을 사용해서 어떻게 그릴까? geom_point를 사용하면 된다.
ggplot(data=data, aes(x=xvariable, y=yvariable)) + geom_point()
를 사용해서 우리의 학업효능감과 학생 삶의 만족도의 산포도를 구해보면 다음과 같다.

이 때 중복되는 값은 다 한점으로 표시되어 산포도의 분포가 얼마나 되는지 알 수 없다 이럴떄는 jitter을 사용해서 이 점들을 약간 흩뿌려주도록 한다. 세로, 가로로 얼마나 흩뿌리고 싶은지 설정이 가능하니까 척도에 맞게 설정할 수 있다.
ggplot(data=data, aes(x=xvariable, y=yvariable)) + geom_point() + geom_jitter(height=.1, width=.1)

xlab과 ylab은 이미 배운 거니 그냥 x축, y축 이름 정하는 거라 하고, scale_x_continuous(breakes=seq(1,7,1))의 의미는, x축 값을 1부터 7인 값까지 나타내되, 사이값은 1마다 나타내라 라는 뜻이다. scale_y_continuous 역시 마찬가지. 또 산포도에서 line of best fit (최적선)을 나타내기 위해선, geom_smooth를 사용한다. 색을 지정할 수 있고, 아래 예시를 보면 회귀에서 사용한 코드인 lm을 사용해서 methods를 설정해 주었다. 두 변인값 간의 예측 관계를 회귀라고 한다는 점을 다시 상기시켜볼 수 있다.

이제 이 점들을 명명척도에 따라 분류한다고 해보자. 그러면 다음 코드처럼 ggplot(data=chid_data, aes(x=acaefficacy, y=stusatisf, color=as.factor(gender)))으로 수정하여 성별에 따라 색을 다르게 표기하라라는 명령문을 내릴 수 있으며, scale_color_manual을 통해 각각의 수준에 대해 이름붙이고, 색깔 지정까지 할 수 있다.

아래는 요인의 하위수준에 따른 최적선을 표기한 코드! 그냥 코드 보면 다 알기때문에 자세한 내용은 생략하고 넘어가도록 하겠다.

혹시 모르겠는 부분이나 어려운 점 있으면 댓글로 남겨주시면 답변해드릴게요~
'Study > 통계 공부 + R' 카테고리의 다른 글
| 기초통계: 가설 검정 (0) | 2020.12.21 |
|---|---|
| 기초통계: 표준점수 (Z점수; Z score) (0) | 2020.12.18 |
| R 기초: 평가자간 신뢰도 Cohen's kappa, 단순회귀분석 (2) | 2020.12.07 |
| R 기초: 여러 유형의 상관분석 돌리기 (2) | 2020.12.06 |
| R 기초: 기술치(평균, 표준편차 등), 상관, 척도점수 구하기 (2) | 2020.12.06 |




댓글