이번 단순회귀랑 데이타 시각화 글에는 저번에 올린 여러유형의 상관분석 돌리기에 사용했던 데이타를 그대로 사용할 예정이에요! 혹시 모르니 다시 올림(친절). 두개는 같은 파일이고 그냥 엑셀파일인지 씨에스븨 파일인지만 차이 있어요. 선호하시는 것 그대로 다운받으면 됩니다.
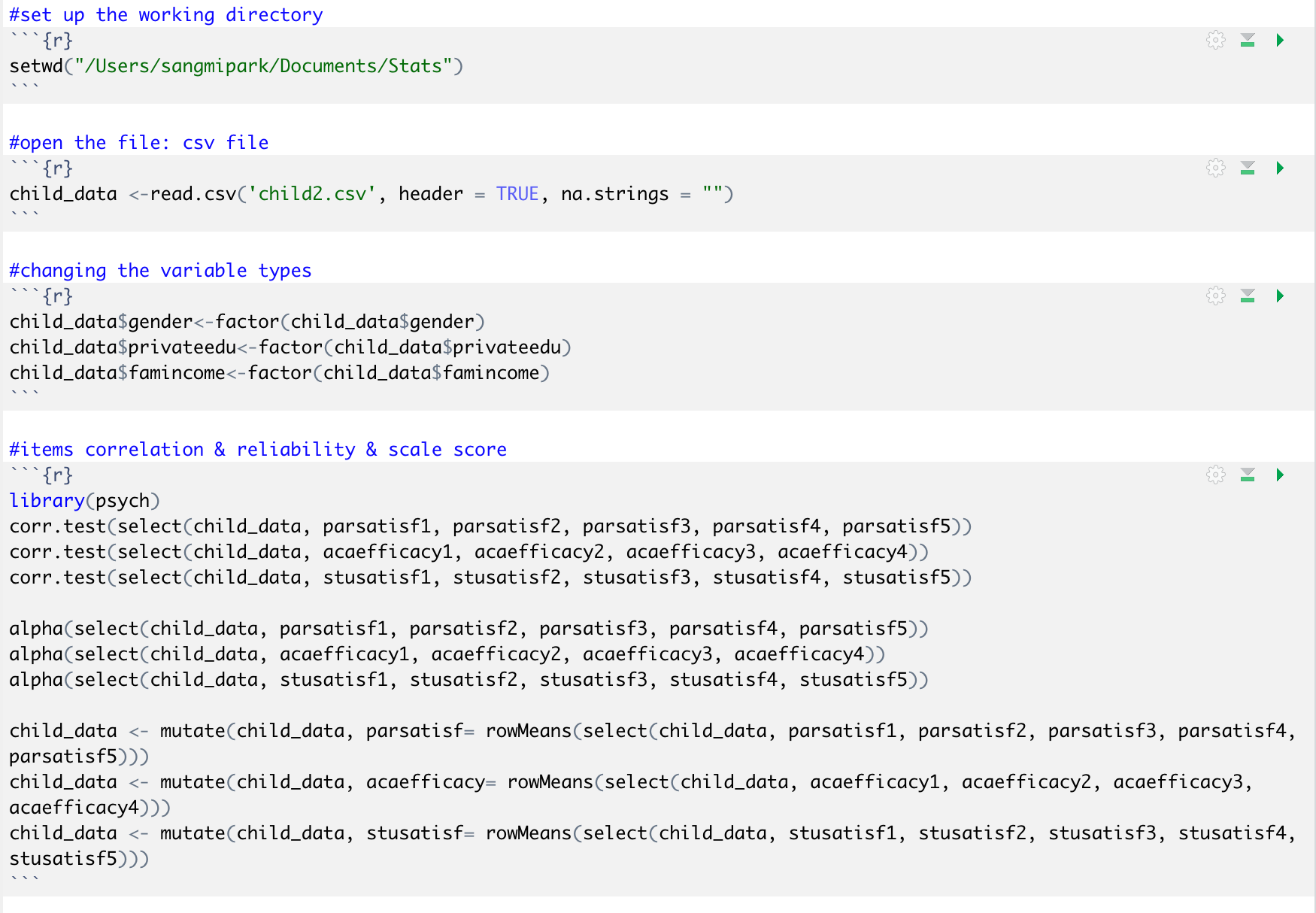
시작하기 전에 그 전에 배웠던 데이타 클리닝을 기반으로 데이타 정리를 좀 해볼게요. 여러유형의 상관분석 돌리기글을 따라 하신 분은 그 코드 그대로 사용하시면 됨! 다음을 순서대로 실행해주었어요. 아래 사진에서 자세한 코드 보실 수 있고, 더 자세한 설명을 원하시는 분은 데이타 클리닝 관련 글 쭉 보시면 됩니다.
1. 작업디렉토리 설정
2. 데이타 파일 열기
3. 변인 유형 설정
4. 문항 간 상관 확인(이번 데이타는 역코딩 문항이 없어요), 신뢰도 확인, 그리고 척도 점수 만들기
단순회귀를 중다회귀랑 같이 올릴까 고민하다가, 다변량은 나중에 올리기로 하고 Cohen's kappa 구하는 법을 추가하기로 했어요. 먼저 평가자간 신뢰도(inter-rater reliability)를 알려주는 코헨스 카파 구하는 법을 알아볼게요.
평가자간 신뢰도(inter-rater reliability)
평정자간 신뢰도라고도 하는 이 평가자간 신뢰도는 무엇일까요? 예를 들어 우리가 설문조사가 아니라 인터뷰나 혹은 어머니와 아기가 상호작용하는 모습을 비디오로 측정한 자료 등을 분석한다고 해볼게요. 양적연구를 하기 위해서는 그 자료를 양적 자료로 바꿔야겠죠. 즉 수학적으로 자료를 변환하게 됩니다. 구체적으로 미국에 있는 아시안을 대상으로 인종 차별 경험을 인터뷰했다고 해봐요, 여러가지 유형의 차별 경험이 나오겠죠. 아시안은 똑똑하고 일을 열심히 한다는 스테레오타입(고정관념)에 노출되기도 하고, "where are you from?" 이라며 아시안 아메리칸들을 자신과는 다르고 이 미국에 실질적으로 속하지 않는다는 마이크로어그레션을 표출하기도 하겠죠 (자신들도 영국에서 왔으면서 말이에요^^). 아니면 직접적으로 혐오 표현을 겪을 수도 있어요(길가다가 갑자기 고투헬이라고 누가 소리친다던지 등). 아시안을 대상으로 한 인터뷰에서 이러한 경험을 각각 "positive stereotype", "microaggression", "direct racism" 으로 코딩한다고 해볼게요. 사람마다 생각이 다를 수 있으므로, 한명만 코딩을 하면 데이터에 대한 신뢰도가 낮을 수 있죠. 만약 여러명이 코딩했는데 그 코딩이 전부 유사하게 나왔다면? 신뢰도가 높다고 할 수 있습니다. 이를 평가자간 신뢰도라고 해요. (참고로 평가자간 신뢰도는 검사 타당도의 일부에 속합니다.)
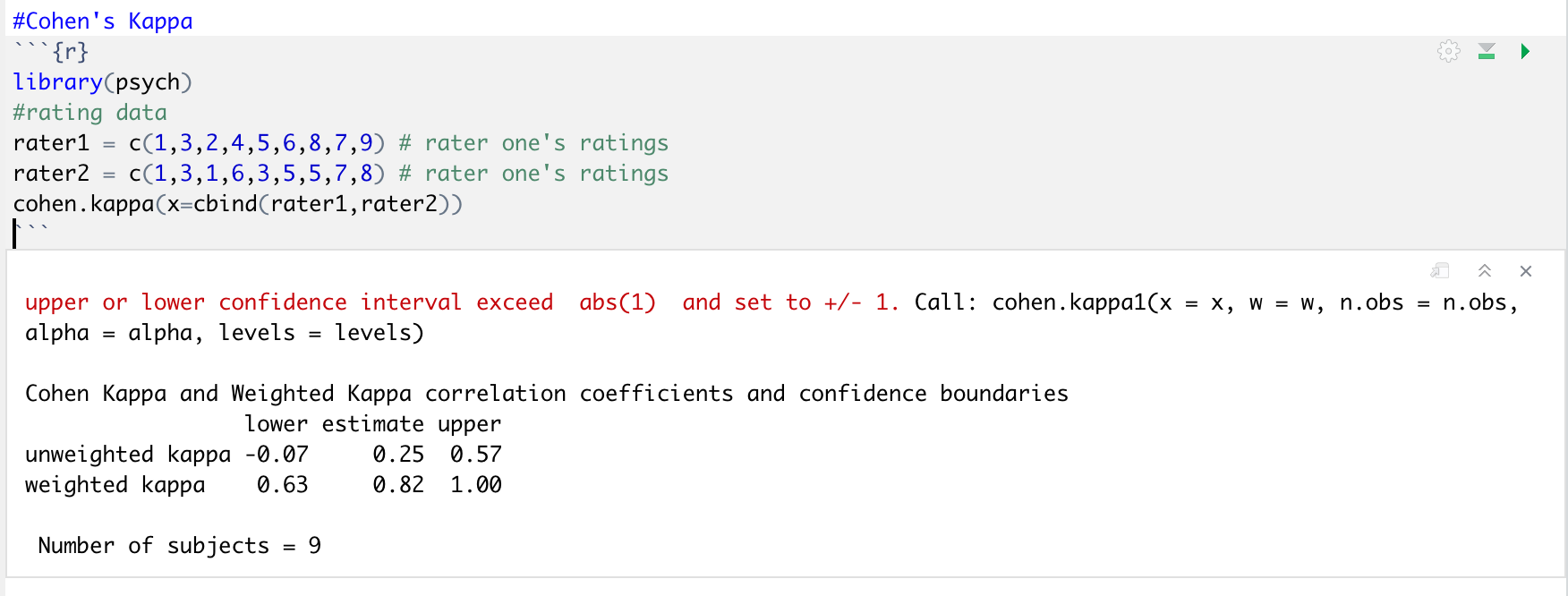
이 평가자간 신뢰도를 측정하는 데 가장 많이 사용하는 것이 "코헨의 카파(Cohen's Kappa)"입니다. 그냥 우리가 가진 데이타에서 그대로 사용할게요. 인터뷰를 통해 각각의 참여자가 겪은 positive stereotype을 연구할 때, positive stereotype을 보고한 빈도를 두명의 평가자가 코딩했다고 해봅시다.
| 평가자 1 | 평가자 2 | |
| 참여자 1 | 1 | 1 |
| 참여자 2 | 3 | 3 |
| 참여자 3 | 2 | 1 |
| 참여자 4 | 4 | 6 |
| 참여자 5 | 5 | 3 |
| 참여자 6 | 6 | 5 |
| 참여자 7 | 8 | 5 |
| 참여자 8 | 7 | 7 |
| 참여자 9 | 9 | 8 |
그러면 이 데이타를 R로 불러올 수도 있지만, 데이타값을 입력해줄 수도 있어요. 이를 위해선 다음의 명령어를 사용합니다.
rater1 = c(1, 3, 2, 4, 5, 6, 8, 7, 9)
rater2 = c(1, 3, 1, 6, 3, 5, 5, 7, 8)
이제 두 평가자의 데이터가 생겨났어요. 이제 코헨 카파값을 구할게요. 아래 코드를 사용해서 카파값을 구해주세요. 참고로 cbind는 콜럼을 묶어주라는 명령문입니다.
cohen.kappa(x=cbind(rater1, rater2))
참고로, 두 평가자의 평정 값을 하나의 데이터 합치고싶다면, 이를 data<-cbind(rater1, rater2)로 사용하면 rater1과 rater2 콜럼을 포함한 데이터가 생깁니다. 이런 경우 그 data를 사용해 직접 카파값을 구할 수도 있겠죠: cohen.kappa(data)
만약 어떤 큰 데이터 셋 내에 rater 데이타이 포함되어 있는 경우라면 다음처럼 사용할 수 있습니다.
cohen.kappa(x=cbind(data$rater1, data$rater2))
우리가 가지고 있는 데이타셋 중에 parsatisf, stusatisf 데이타를 사용해서 돌려봤어요. 이 두 변인은 평가자 평정 데이터는 아니지만 평가자 평정 데이터라고 가정하고 봐주세요~!

단순선형회귀(simple linear regression)
단순회귀를 R에서 돌리는 것도 엄청 간단해요. 회귀에 대한 이론적 내용은 https://daily1123.tistory.com/entry/기초통계-이변량통계3-단순-선형-회귀-분석 에서 참고하시고 여기서는 R 에서 분석하는 법만 다룰게요. 단순회귀는 lm 명령어를 사용해서 돌릴 수 있습니다. 아래 코드를 잘 보시면, 데이타셋을 지정해주고, 독립변인이 종속변인을 어떻게 예측하는지를 회귀를 사용해 돌린 것을 name이라고 지정하고, 그 name이라는 회귀에 대한 정보를 보여달라는 명령문임이 보일 거에요.
name<-lm(dependentvar~independentvar, data=data)
summary(name)
우리의 데이타셋에서 예를 들어, 학생의 학업효능감은 학생의 삶의 만족을 예측해줄 수 있다고 가설을 세웠다고 해볼게요. 그러면 다음처럼 코드를 작성하면 되겠죠.
student <- lm(stusatisf~acaefficacy,data=child_data)
summary(student)
실제로 두 코드를 실행하면 다음과 같은 결과를 볼 수 있어요.

제일 아랫줄에 F-statistic이 나와요. 즉, 우리는 결과를 페이퍼에 보고할 때 F(1, 297) = 71.89, p < .001이라고 보고할 수 있고, 유의미한 결과를 얻었으니 학생의 학업효능감은 삶의 만족도를 유의미하게 예측해준다고 말할 수 있겠죠. 이 F 값은 회귀 전체에 대한 분석에 대한 수치이므로, 변인1(학업효능감)과 변인2(삶의만족도)의 관계에 대한 수식, 즉 y=ax+b에 대한 값을 구하려면 위 coefficients에 있는 값을 봐야합니다.
Estimate콜럼에 절편이랑 학업효능감row에 있는 값을 각각 b와 a 넣어주면 (이때 반올림하여 소수점 두자리까지 표시한다).
삶의만족도 =. 40(학업효능감)+1.77 가 되고
즉, 학업효능감이 1단위 높을수록 삶의 만족도는 .40만큼 증가함을 예측할 수 있다라고 보면 됩니다.
회귀 역시 상관을 기반으로 하기때문에 인과관계를 보장해주지 못하고, 그냥 예측만 해줄 뿐임을 기억해야해요. 인과관계에 대하여 회귀를 통해 얘기하고 싶다면, 선행 연구를 기반으로 인과관계를 가정하는 정도로 얘기해볼 수 있어요. 통계분석이 물론 중요하지만 꼭 문헌리뷰를 바탕으로 한 통계분석을 해야합니다. R 공부할 때는 그냥 이 변인, 저 변인 넣어서 돌려보지만 실제 연구할 때는 꼭 문헌리뷰가 선행되어 이를 바탕으로 해야함을 기억해주세요.
'Study > 통계 공부 + R' 카테고리의 다른 글
| 기초통계: 표준점수 (Z점수; Z score) (0) | 2020.12.18 |
|---|---|
| R 기초: 데이타 시각화. 예쁘고 깔끔한 그래프 그리기 (0) | 2020.12.08 |
| R 기초: 여러 유형의 상관분석 돌리기 (2) | 2020.12.06 |
| R 기초: 기술치(평균, 표준편차 등), 상관, 척도점수 구하기 (2) | 2020.12.06 |
| R 기초: 데이타 클리닝(결측치 다루기) (0) | 2020.12.05 |




댓글